
Разберем на примерах, что происходит на уровне СУБД при выполнении различных действий в конфигураторе и пользовательском режиме.
Для примера создадим пустую конфигурацию и создадим в ней некоторые справочники и документы. Так будет выглядеть структура справочников и документов.

Создадим остаточный регистр накопления без режима разделения итогов. Добавим движения для документа по этому регистру.
Для удобства работы будем использовать MS SQL Server и инструмент Profiler, для других СУБД поведение будет примерно таким же. На уровне СУБД наша база теперь выглядит так:
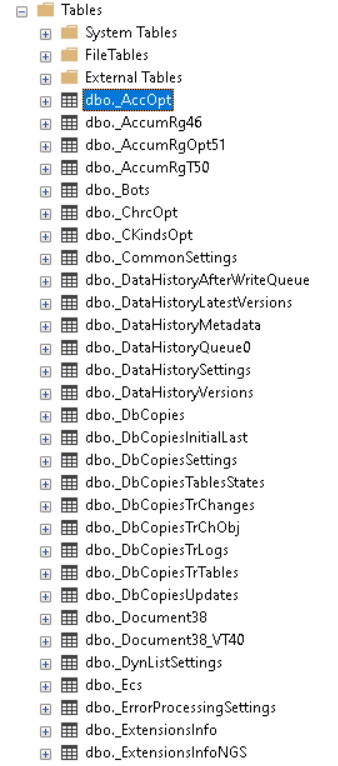
Для остаточного регистра создалось 3 таблицы — непосредственно таблица регистра ([dbo].[_AccumRg46]), таблица опций ([dbo].[_AccumRgOpt51]) и таблица остатков ([dbo].[_AccumRgT50]). Обратите внимание, что номера у всех таблиц регистра разные.
В пользовательском режиме создадим две номенклатуры — «Стол» и «Стул», четыре склада, две серии, а также четыре документа, на каждый склад по одному документу.
Рассмотрим данные, которые были записаны в каждую из таблиц регистра накопления. Физическая таблица регистра:
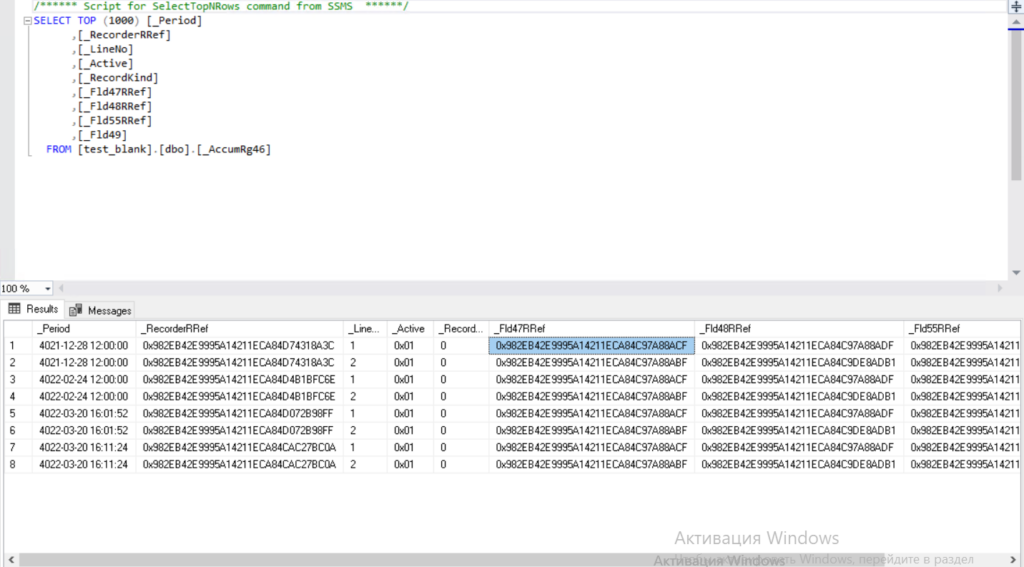
В ней мы видим записи регистра, если посмотреть на колонку «_Period», то можно увидеть, что там год не 2021, а 4021. Так происходит из-за того, что 1С хранит дату как тип данных datetime, а в СУБД MS SQL этот тип данных хранит в диапазоне от 01.01.1753 до 31.12.9999. С обычными датами, где фигурирует дата и время, все в порядке, но 1С сохраняет время как дату, т.е. получается 01.01.0001 13:00, что уже приводит к ошибке.
Колонки, которые начинаются с префикса _Fld — это пользовательские поля, которые добавлены через конфигуратор. Колонка _RecorderRRef — это ссылка на документ, здесь все просто, его можно найти в соответствующей таблице документов.
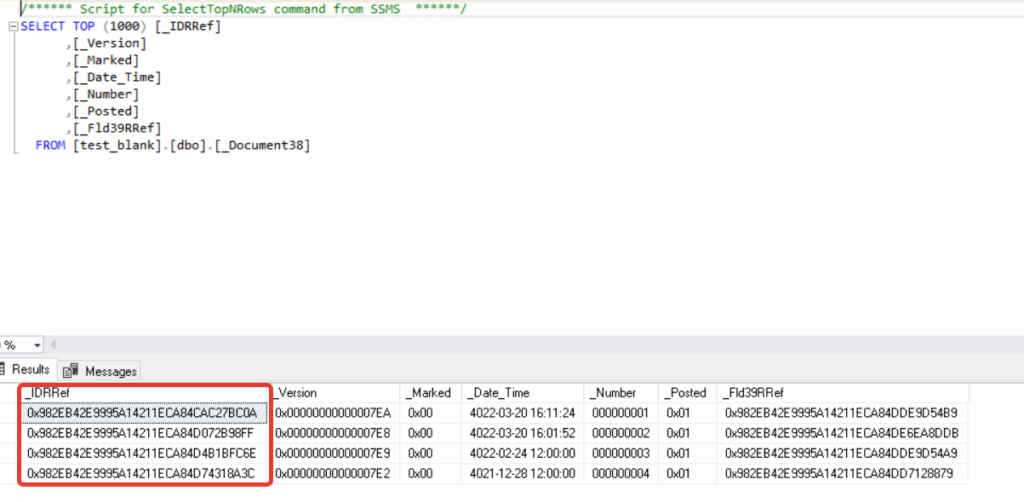
У документа мы тоже видим служебные колонки и поле _Fld*, это шапка документа, в нашем случае ссылка на склад. Данный принцип применим и к остальным ссылочным полям, которые созданы в конфигураторе.
Следующие таблицы в регистре интереснее, они используются для ускорения и обслуживания регистра. В таблице опций (_AccumRgOpt) всегда находится одна строка.
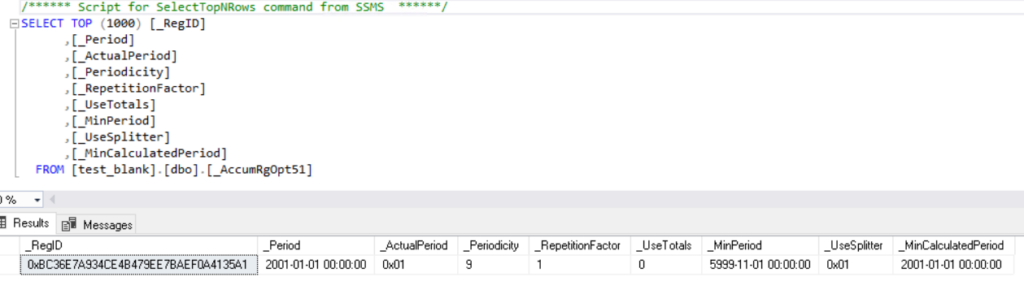
В таблице _AccumRgT50 хранятся остатки.
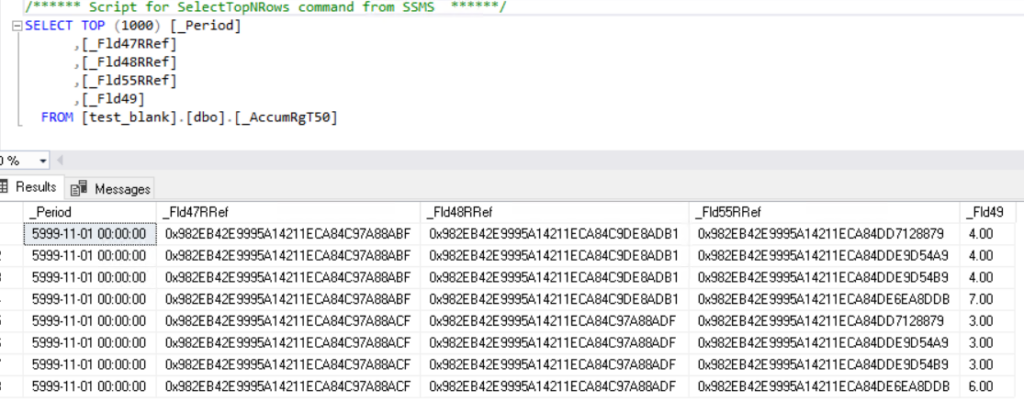
Так как у нас все документы созданы по разным регистрам, то таблица остатков по содержанию совпадает с физической таблицей регистра. Попробуем перенести один из документов на другой склад. Получаем следующую картину:
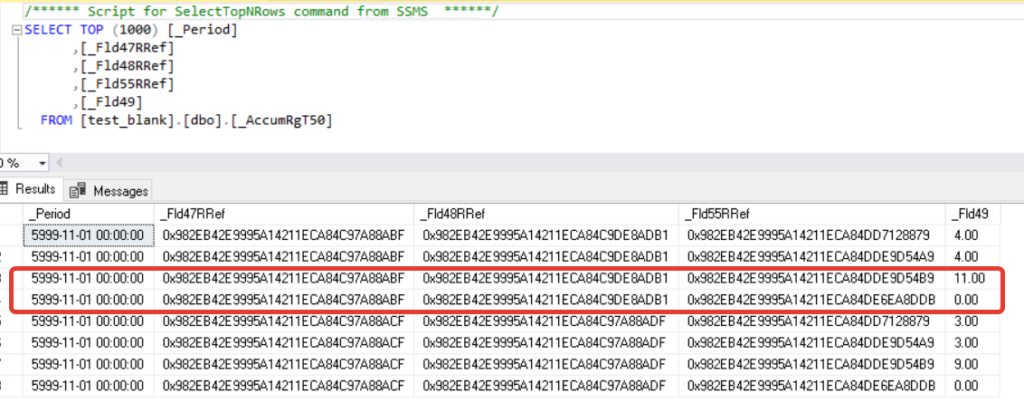
Обратите внимание на выделенные строки, в них по старому складу сейчас числится 0, так как мы изменили его в документе, а по новому складу остатки сложились. Для того, чтобы убрать строки с нулевыми остатками, необходимо сделать пересчет итогов. После пересчета итогов:
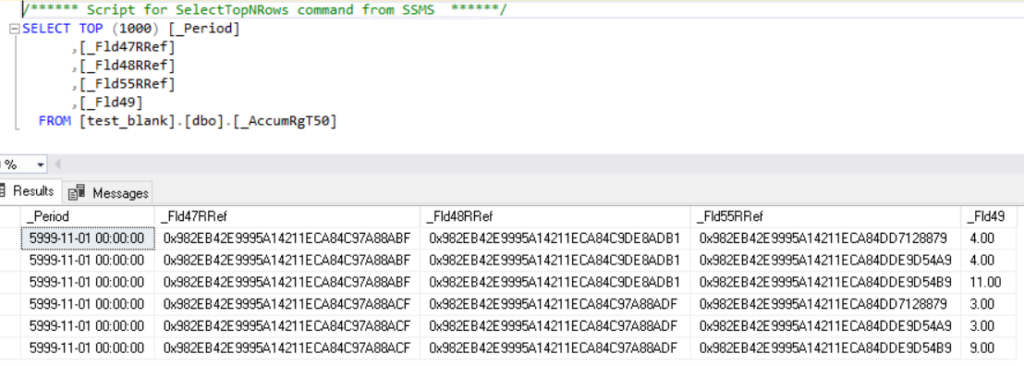
Поэтому не пренебрегайте пересчетом итогов, они позволяют сделать таблицу итогов меньше. А также при разработке обязательно учитывайте, что для остаточного регистра должны быть как процедуры прихода, так и расхода, и после выполнения необходимых приходов и расходов, остаток должен быть равен нулю, никаких копеек, никаких граммов оставаться не должно. Иначе таблица итогов будет увеличиваться в размерах и начинать тормозить.
Рассмотрим запросы к остаточному регистру. Для этого напишем в консоли следующий запрос и выполним его:
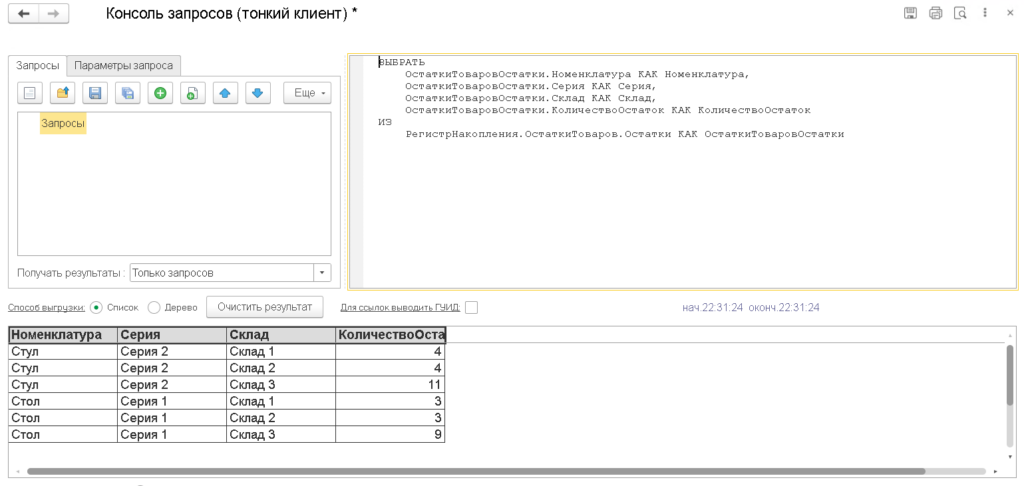
Здесь мы получаем остатки по регистру по всем измерениям. Посмотрим что происходило на сервере СУБД:
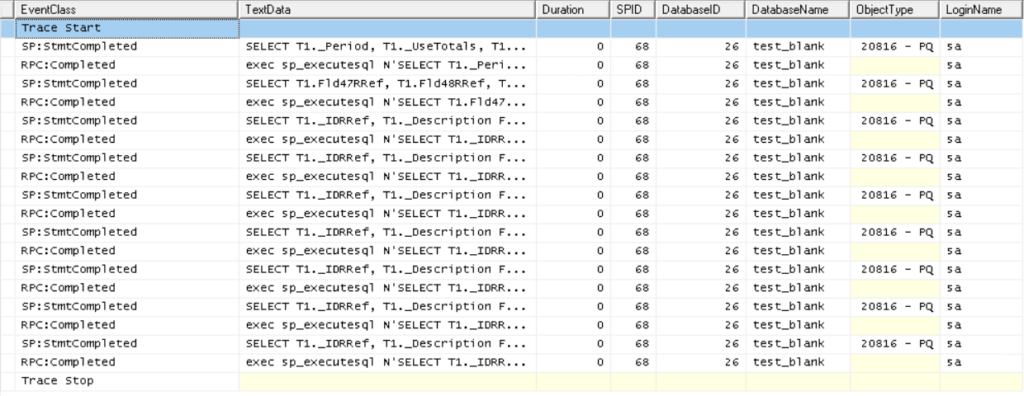
Как видим выполнилось достаточно много запросов. Первый запрос получает таблицу опций регистра:
SELECT
T1._Period,
T1._UseTotals,
T1._ActualPeriod,
T1._UseSplitter,
T1._MinPeriod,
T1._MinCalculatedPeriod
FROM dbo._AccumRgOpt51 T1
WHERE T1._RegID = @P1Второй запрос получает остатки:
SELECT
T1.Fld47RRef,
T1.Fld48RRef,
T1.Fld55RRef,
T1.Fld49Balance_
FROM (SELECT
T2._Fld47RRef AS Fld47RRef,
T2._Fld48RRef AS Fld48RRef,
T2._Fld55RRef AS Fld55RRef,
T2._Fld49 AS Fld49Balance_
FROM dbo._AccumRgT50 T2
WHERE T2._Period = @P1 AND (T2._Fld49 <> @P2) AND (T2._Fld49 <> @P3)) T1Здесь мы видим, что получение остатков производится через вложенный запрос. При этом просто берутся записи из остатков. В условиях @P2 и @P3 отсекаются строки с нулевым количеством. Остальные же запросы — это получение представлений ссылок, которые мы видим в результате выполнения запроса в консоли запросов.
SELECT
T1._IDRRef,
T1._Description
FROM dbo._Reference36 T1
WHERE T1._IDRRef = @P1Примечательно, что если код выполнять программно, то данных запросов не появляется, но их можно вызвать, если поставить в конфигураторе точку останов и попробовать прочитать результат переменной из выборки.
Чтобы избежать такого большого количества запросов, если нужны не ссылки, а представления, то выбирать необходимо именно представления:

Здесь мы уже видим только два запроса — получение опций регистра и получение остатков, но запрос по получению остатков несколько усложнился, он присоединяет к себе таблицы справочников. Данный подход более оптимальный, особенно если сервер 1С и СУБД находятся на разных компьютерах.
SELECT
T3._IDRRef,
T3._Description,
T4._IDRRef,
T4._Description,
T5._IDRRef,
T5._Description,
T1.Fld49Balance_
FROM (SELECT
T2._Fld47RRef AS Fld47RRef,
T2._Fld48RRef AS Fld48RRef,
T2._Fld55RRef AS Fld55RRef,
T2._Fld49 AS Fld49Balance_
FROM dbo._AccumRgT50 T2
WHERE T2._Period = @P1 AND (T2._Fld49 <> @P2) AND (T2._Fld49 <> @P3)) T1
LEFT OUTER JOIN dbo._Reference36 T3
ON T1.Fld47RRef = T3._IDRRef
LEFT OUTER JOIN dbo._Reference37 T4
ON T1.Fld48RRef = T4._IDRRef
LEFT OUTER JOIN dbo._Reference54 T5
ON T1.Fld55RRef = T5._IDRRefПопробуем выбрать не все измерения из регистра, а только одно, например номенклатуру. Как известно, платформа в результате вернет итоговые остатки в разрезе номенклатуры.
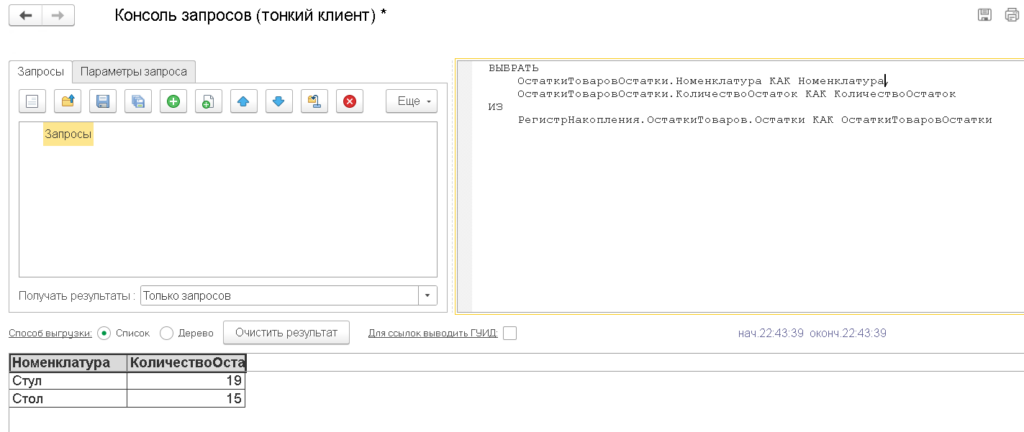
В итоге получаем следующий запрос:
SELECT
T1.Fld47RRef,
T1.Fld49Balance_
FROM (SELECT
T2._Fld47RRef AS Fld47RRef,
CAST(SUM(T2._Fld49) AS NUMERIC(22, 2)) AS Fld49Balance_
FROM dbo._AccumRgT50 T2
WHERE T2._Period = @P1 AND (T2._Fld49 <> @P2) AND (T2._Fld49 <> @P3)
GROUP BY T2._Fld47RRef
HAVING (CAST(SUM(T2._Fld49) AS NUMERIC(22, 2))) <> 0.0) T1В нем мы видим, что появляется группировка (GROUP BY) во вложенном запросе, количество суммируется (SUM) и выражается (CAST) как число длиной 22 и точностью 2, а также добавляется функция ИМЕЮЩИЕ (HAVING), которая выводит только ты строки, в которых количество не равно нулю. Это более тяжелые функции, чем просто получить значения, поэтому логично предположить, что регистр накопления желательно проектировать так, чтобы получение остатков в основном происходило в разрезе всех измерений.